.png?width=347&height=97&name=Data%20Council%20AI%20logo%20(1).png "Data Council")

Read More


In this blog series leading up to our SF18 conference, we invite our featured startups to tell us more about their data engineering challenges. Today, we speak with NuCypher, an early-stage company building a decentralized encryption service.


In this blog series leading up to our SF18 conference, we invite our featured startups to tell us more about their data engineering challenges. Today, we speak with PipelineAI, a startup helping you to continuously train, optimize and host deep learning models at scale.

In this blog series leading up to our SF18 conference, we invite our featured startups to tell us more about their data engineering challenges. Today, we speak with Instrumental, an early-stage company building data systems to monitor and improve manufacturing line performance.

In this blog series leading up to our SF18 conference, we invite our featured startups to tell us more about their data engineering challenges. Today, we speak with Pachyderm, an early-stage company building a data platform for data science.
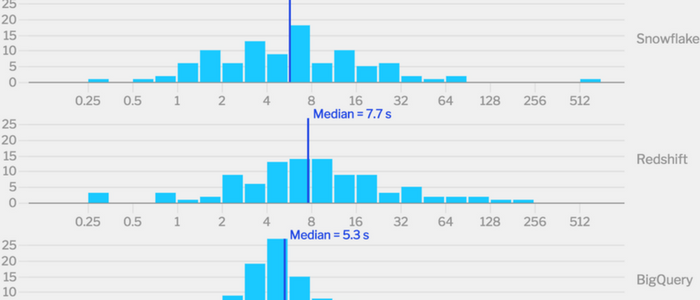
Fivetran is a data pipeline that syncs data from apps, databases and file stores into our customers’ data warehouses. The question we get asked most often is “what data warehouse should I choose?” In order to better answer this question, we’ve performed a benchmark comparing the speed and cost of three of the most popular data warehouses — Amazon Redshift, Google BigQuery, and Snowflake.

Batch data processing — historically known as ETL — is extremely challenging. It’s time-consuming, brittle, and often unrewarding. Not only that, it’s hard to operate, evolve, and troubleshoot.
In this post, we’ll explore how applying the functional programming paradigm to data engineering can bring a lot of clarity to the process. This post distills fragments of wisdom accumulated while working at Yahoo, Facebook, Airbnb and Lyft, with the perspective of well over a decade of data warehousing and data engineering experience.