.png?width=347&height=97&name=Data%20Council%20AI%20logo%20(1).png "Data Council")
Recently at a conference, I had the privilege of demonstrating MemSQL processing over a trillion rows per second on the latest Intel Skylake servers.
It’s well known that having an interactive response time of under a quarter of a second gives people incredible satisfaction. When you deliver response time that drops down to about a quarter of a second, results seem to be instantaneous to users.
But with large data sets and concurrency needs, giving all customers that level of speed can seem beyond reach. So developers sometimes take shortcuts, such as precomputing summary aggregates. That can lead to a rigid user experience where if you tweak your query a little, for example adding an extra grouping column, suddenly it runs orders of magnitude slower. And it also means your answers are not real time, i.e. not on the latest data.
MemSQL gives you the interactive response time your users want, on huge data sets, with concurrent access, without resorting to precomputing results.
Running at a Trillion Rows Per Second
MemSQL 6, which shipped in late 2017, contains new technology for executing single-table group-by/aggregate queries on columnstore data incredibly fast. The implementation is based on these methods: (1) operations done directly on encoded (compressed) data in the columnstore, (2) compilation of queries to machine code, (3) vectorized execution, and (4) use of Intel AVX2 single instruction, multiple data (SIMD) enhancements. When the group-by columns are encoded with dictionary, integer value, or run-length encoding, MemSQL runs a one-table group-by/aggregate at rates exceeding three billion rows per second per core at its peak. The fewer the number of groups and the simpler the aggregate functions, the faster MemSQL goes.
This incredible per-core speed gave us the idea to shoot for the trillion-rows-per-second mark. To accomplish this, with a realistic query, I wrote a data generator to build a data set that simulates stock trades on the NASDAQ. Then we talked to our partners at Intel, and they generously gave us access to servers in their lab with the latest Skylake processors. These machines have two Intel® Xeon® Platinum 8180 processors each, which have 28 cores, for a total of 56 cores per server. I created a MemSQL cluster with one aggregator node and eight leaf nodes, with one server for each node, as shown in Figure 1. This cluster had 2 * 28 * 8 = 448 total cores on the leaves — the most important number that determined the overall rows-per-second rate we could get.
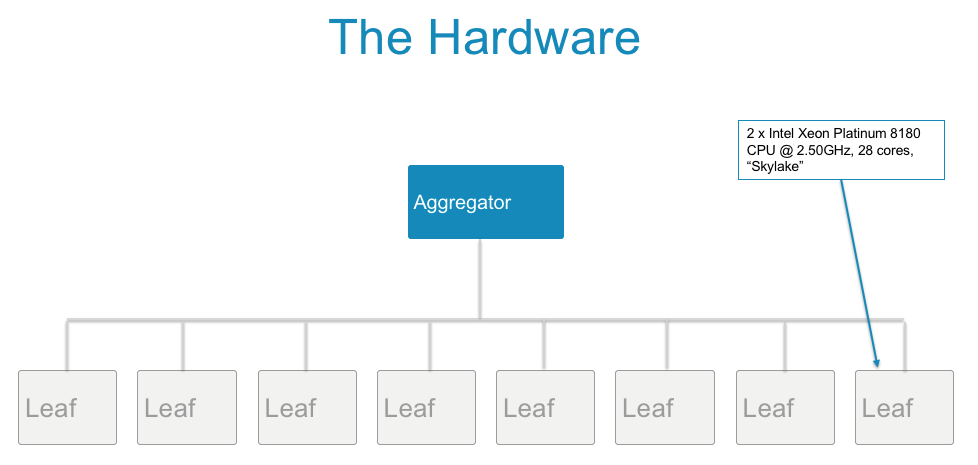
Figure 1. The hardware arrangement used to break a trillion rows per second.
I installed MemSQL on this cluster with two MemSQL leaf nodes on each leaf server, with non-uniform memory access (NUMA) optimizations enabled, so each MemSQL leaf node software process would run on a dedicated Skylake chip. Then I created a database trades with one partition per core to get optimal scan performance. Once that was complete, I loaded billions of rows of data representing stock trades (really decades worth of trades) into a table called trade. The larger capitalization a stock is, the more trades it has. Here’s a tiny sample of the data:
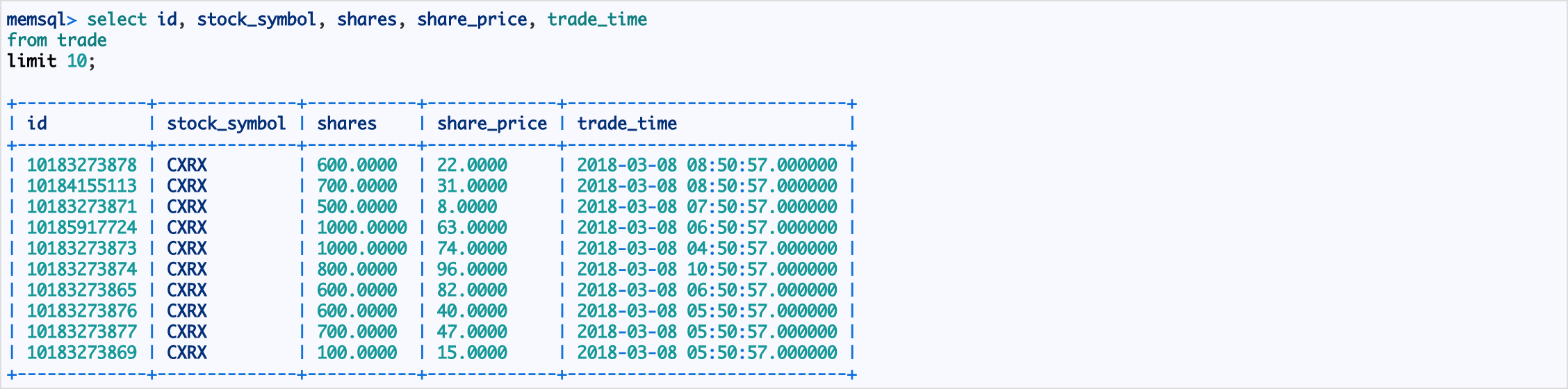
This resulted in how many rows? Check this out:

That’s right, about 57.8 billion rows!
Then I ran this query to find the top 10 most traded stocks of all time:

And got this result:

10 rows in set (0.05 sec)
Yes, this query ran in 5 one-hundredths of a second! To get an accurate scan rate, we need some more significant figures though. So I wrote a stored procedure to run it 100 times in a loop:

Yes, that is 1.28 trillion rows per second!
We’re scanning and processing 2.86 billion rows per second per core, through the beauty of operations on encoded data, vectorization, and SIMD. We’re actually spending some time on every row, and not precalculating the result, to achieve this.
What does it mean?
The fact that we can break the trillion-row-per-second barrier with MemSQL on 448 cores worth of Intel’s latest chips is significant in a couple of ways. First, you can get interactive response time on mammoth data sets without precalculating results. This allows more flexible interaction from users, and encourages them to explore the data. It also enables real-time analytics. Second, it allows highly concurrent access by hundreds of users on smaller data sets, with all of them getting interactive response times. Again, these users will get the benefit of analytics on the latest data, not a precalculated summary snapshot. MemSQL enables all this through standard SQL that your developers already are trained to use.
Also, we achieved this on industry-standard hardware from Intel, not a special-purpose database machine. These are machines that your organization can afford to buy, or that you can rent from your favorite cloud provider, without zeroing out your bank account.
Appendix: For you hardware geeks out there
If you’re craving more details about the Skylake chips we used, here’s the output of the Linux lscpu utility run on one of the servers making up the 9 total servers in the cluster:

The data was stored on SSDs, though that isn’t really significant since we ran the queries warm-start, so the data was already cached in memory. The network is 10-gigabit ethernet.
Check out Eric's upcoming DataEngConf SF '18 talk where he dives deep into more detail on this topic.
This post was originally published on MemSQL's blog.