.png?width=347&height=97&name=Data%20Council%20AI%20logo%20(1).png "Data Council")
OpenLineage is an API for collecting data lineage and metadata at runtime. While initiated by Datakin, the company behind Marquez, it was developed with the aim to create an open standard. As Datakin’s CTO Julien Le Dem explained in a blog post announcing the launch, OpenLineage is meant to answer the industry-wide need for data lineage, while making sure efforts in that direction aren’t fragmented or duplicated.
Only time will tell if it achieves this goal, but its circle of supporters already includes contributors from other major open-source data projects: Airflow, Amundsen, DataHub, dbt, Egeria, Great Expectations, Iceberg, Pandas, Parquet, Prefect, Spark, and Superset. As for Marquez, which is now an LF AI & Data project, it is the reference implementation of the OpenLineage API.
If so many project creators are involved, it’s because OpenLineage doesn’t intend to replace them. Instead, its purpose is to “guarantee the compatibility and consistency of the metadata produced by their respective solutions.”
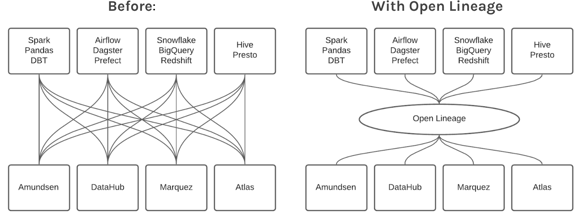 Key characteristics of OpenLineage include defining a generic model of job/dataset/runs entities; consistent naming strategies for jobs and datasets; and the ability to define specific facets that can enrich those entities.
Key characteristics of OpenLineage include defining a generic model of job/dataset/runs entities; consistent naming strategies for jobs and datasets; and the ability to define specific facets that can enrich those entities.
To learn more, make sure to check out Julien Le Dem’s Metaspeak 2020 talk. You can also follow OpenLineage on Twitter and request access to the community’s Google group & Slack.