.png?width=347&height=97&name=Data%20Council%20AI%20logo%20(1).png "Data Council")
DataHub is a generalized metadata search & discovery tool. Originally created at LinkedIn, it was open sourced in February of this year, and has been adopted by other companies such as Expedia and Typeform, with the ambition to help connect employees to data that matters to them.
Its origin story is similar to the one of data catalogs like Airbnb’s Data Portal or Lyft’s Amundsen: data discovery at hyperscale is a problem that calls for specific tools. However, DataHub also takes things one step further than its predecessor at LinkedIn, WhereHows: in addition to boosting the productivity of data users, it also has its eye on AI/ML and “power[ing] new use cases while preserving fairness, privacy, and transparency.” With this goal in mind, it required an architecture that was able to scale with the metadata, and which is currently the following:
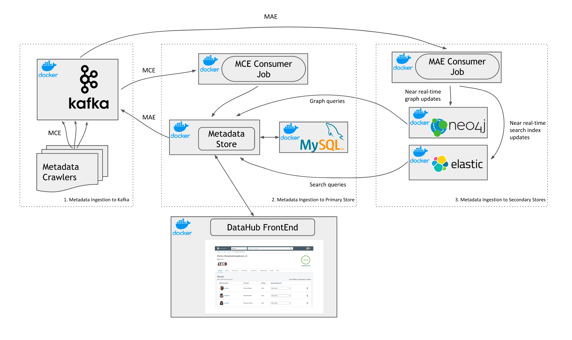
Note that the open source version of DataHub is separate and slightly different from the one LinkedIn maintains in-house. Differences include stream processing: “Although our internal version uses a managed stream processing infrastructure, we chose to use embedded (standalone) stream processing for the open source version because it avoids creating yet another infrastructure dependency,” DataHub contributors Kerem Sahin, Mars Lan, and Shirshanka Das explained in a blog post worth reading.
To learn more, you can check out this recent episode of the Data Engineering Podcast or join DataHub’s Slack, which features channels for discussions around search, graph, UI, k8s, and more.