2026
2025
Sponsor
Podcast
Data Council Talks
Show all
NYC '17
SF '17
NYC '16
Exit Archive
Macrobase: A Search Engine for Fast Data Streams
Sahaana Suri | Stanford University
TimescaleDB: Rearchitecting a SQL database for ...
Mike Freedman | TimescaleDB
Production Analytics With a Distributed Column ...
Sam Stokes | Honeycomb
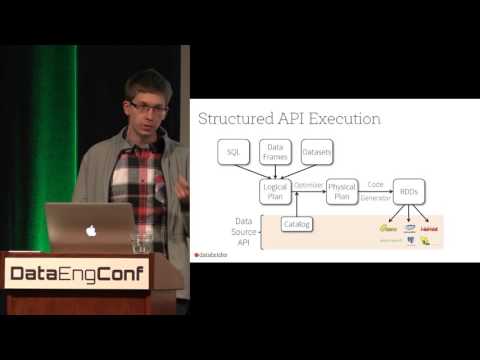
Don’t optimize my queries, optimize my data!
Julian Hyde | Google
Worse Case Scenario in the Database
Marianne Bellotti | United States Digital Service
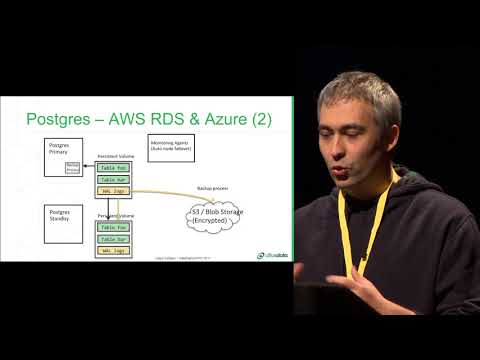
The Challenges of Distributing Postgres: A Citus ...
Ozgun Erdogan | Citus Data
The Statistics of Dirty Data
Sanjay Krishnan | UC Berkeley
Easy, Scalable, Fault-tolerant Stream Processing ...
Burak Yavuz | Databricks
Using Apache Arrow, Calcite and Parquet to build ...
Jacques Nadeau | Dremio
How Spotify Distills Terabytes of Raw Data into ...
Gandalf Hernandez | Spotify
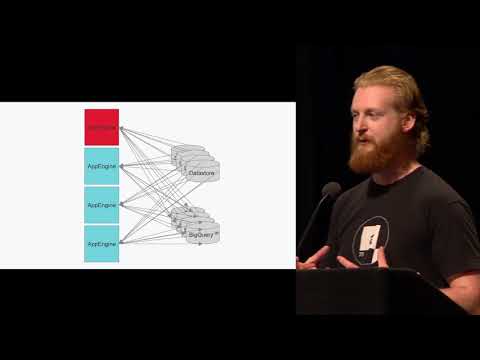
Building a Recursive BigQuery Mapper
Darren McCleary | The New York Times
Building ETL Infrastructure that Analysts Love
Christian Romming | ETLeap
Using Apache Spark for processing trillions of ...
Vadim Semenov | Datadog
Productizing structural models
James Savage | Schmidt Futures
Lessons in hiring data scientists
Genevieve Smith | Insight
Using Causal Forests for Subpopulation ...
James Faghmous | Icahn School of Medicine at Mt. Sinai
You Won't Believe How We Optimize our Headlines
Lucy Wang | BuzzFeed
Deploying Data Science for Distribution of The ...
Anne Bauer | The New York Times
Zip codes and other lies your map told you
Peter Lenz | Near
Automating machine learning
Andreas Mueller | Data Science Institute
Building automated support at Kickstarter
Jeffrey Doker | Kickstarter
Privacy Techniques for Data Science
Jim Klucar | Immuta
The Future of Data Science in the Media
Haile Owusu | Mashable
Composable Interfaces for Parallel Processing in ...
Matei Zaharia | Databricks
Data Science @ Pinterest
Mohammad Shahangian | Pinterest
Data Science in the Enterprise
Sean Anderson | Vectara
Practical Solutions for Annoying Machine Learning ...
Alyssa Frazee | Stripe
Beyond 50,000 Partitions: How Heroku Pushes the ...
Jeff Chao | Heroku
Scaling Up Spark at Facebook – a 60TB Production ...
Shuojie Wang | Facebook
How Superset and Druid Power Real-Time Analytics ...
Max Beauchemin | Preset
Hoodie: An Open Source Incremental Processing ...
Vinoth Chandar | Onehouse
Data for the 99%
Benn Stancil | ThoughtSpot
Payment Fraud in Digital Currency
Soups Ranjan | Revolut
The Limitations of Big Data in Predictive ...
Jennifer Prendki | Alectio
Practical Lessons for Building Machine Learning ...
Sharath Rao | Instacart
An Introduction to Big Data's Unsung Hero: The Log
Liz Bennett | Stitch Fix
Why, When, How: Lessons Learned in Applying Deep ...
Daniel Galron | eBay
Anomaly Detection for Data Quality and Metric ...
Laura Pruitt | Netflix
Cloud-Native Stream Processing
Sid Anand | Apache Software Foundation
Parsing of Diverse Healthcare Data
Chris Hartfield | Clover Health
Interactive Exploratory Analytics with Druid
Fangjin Yang | Imply
InfluxDB Storage Engine Internals
Paul Dix | InfluxData
A Nation of Immigrants: The Data Sciences
Kenneth Sanford | Dataiku
Twitter Heron: The Path Towards Elastic Streaming
Ashvin Agrawal | Microsoft
Simulation-based Inference: Advantages Over A/B ...
Nelson Ray | Opendoor
Format Wars: from VHS and Beta to Avro and Parquet
Silvia Oliveros Torres | Silicon Valley Data Science
Real-time System Computing Engines
Steffen Peter | Levyx
The Right Stuff: Lessons Learned from a Decade of ...
Ben Hamner | Kaggle
How Engineer Angels Evaluate Data-Oriented ...
Jocelyn Goldfein | Zetta
The Future of Column-Oriented Data Processing ...
Julien Le Dem | Datadog
Computational Social Science: Exciting Progress & ...
Duncan Watts | Microsoft Research
Causal Inference in Data Science From Prediction ...
Amit Sharma | Microsoft Research
Reinforcement Learning for Data Scientists
Brian Farris | Bloomberg
How to Change a City with Data Science
Ben Wellington | Two Sigma
Python Data Wrangling: Preparing for the Future
Wes McKinney | Posit
Lessons Learned Optimizing NoSQL for Apache Spark
John Musser | Ford Motor Company
Unified Pipeline Architecture: The Evolution of ...
Erin Palmer | Spotify
SystemML & Spark: a Framework for Scalable Data ...
Jerome Nilmeier | IBM
Stop Obsessing about Data Infrastructure
Yair Weinberger | Alooma
Apache Kafka and the Rise of Stream Processing
Guozhang Wang | Confluent
Genomic Data Analysis with Spark & Hadoop
Ryan Williams | Icahn School of Medicine at Mount Sinai
Anomaly Detection for Real-World Systems
Manojit Nandi | STEALTHbits
Building a Cloud-Native SQL Database
Alex Robinson | Cockroach Labs
To Get the Value, Ditch the Hype
Nick Ursa | The New York Times
Statistical and Computational Challenges of ...
Jeiran Jahani | Chartbeat
Predicting Chaotic Systems with Sparse Data: ...
David Kelly | New York University
The Trials and Tribulations of Scaling Data ...
Ashley Miller | Datadog
Peloton: The Self-Driving Database Management ...
Andy Pavlo | Carnegie Mellon University
Elastic Big Data Platform at Datadog
Doug Daniels | Datadog
Processing Geographic Data at Internet Scale
Peter Lenz | Near
Bias, Variance and Adaptive Products
George Davis | Frame.ai
Career Panel - Leveling Up in Your Career as a ...
Nick Chamandy | Lyft
VC Panel - The Present Future of Data-Oriented ...
Matt Hartman | Betaworks
Scalability! But at What COST?
Frank McSherry | Materialize
Reducing Student Loans with Bot-Powered Humans
William Falcon | Facebook / NYU
Building Bots, Building Blocks: How Forbes ...
Luis Capelo | Forbes
https://www.datacouncil.ai/hubfs/DataEngConf/Data%20Council/Sample%20Backgrounds/bg2.jpg
center center
.png?width=1792&height=578&name=Data%20Council%20AI%20logo%20(1).png "Data Council")